
It’s kind of this mystical thing, a “hackathon,” to new programmers. It’s something that everybody mentions casually, you technically understand what it is, but it just feels so alien, at least to me. Maybe that’s just my Tennessee showing.
But, finally, after signing up and preparing for a series of hackathons that ended in extremely sudden cancellations, I finally attended my first at SBHacks at the beautiful campus of UC Santa Barbara.

I arrived there after a 5 hour bus ride and was just blown away by the people and the crowd and the hardware and the whole scene. It was a awesome and at the same time kind of intimidating scene. Most of my friends bailed, but I was not gonna pass up a chance to go to my first hackathon, or even a chance to visit Santa Barbara for free, so I went on my own. Honestly, it was a little intimidating to walk in and see all these hackers super intense, planning their crazy VR-AR-ML-API based projects in literally every corner of the room.
I went, and found a spot to sit down and set up all my gear (i.e. my laptop and water bottle). Then, all of a sudden, I hear a guy from UCLA next to me say something about being from Nashville, which I thought was crazy, finding another Tennessian right next to me at a UCSB hackathon. So I got his attention, and talked for about 10 second when I realized –I KNEW HIM!! I met this guy 3 years ago at a high school conference for three days; we hit it off, but never really kept in touch. Now, 3 years later, at a Hackathon in UCSB, we ended up sitting RIGHT NEXT to each other!

So that broke the intimidation factor of the hackathon for me, and at that point, I started going around talking to people to form a team. I ran into a guy I knew from USC named Tejas who was also reasonable experienced in Deep Learning so we joined up. Then, two girls from UCLA and one guy from USC each approached us looking for a team: they didn’t have much experience, but in my early learning phases, I could have benefited a lot from a little guidance, so I was pretty eager to let them in, and maybe help them out by showing them some web-dev/python basics.
So from there, at about 8:30, we started brainstorming problems people have. I’m a very adamant believer in shouting out literally any thought that pops into your head, so I pushed the whole team to say anything that came to mind. We started with the issue of long bus rides, as we all went on the same long bus ride. From there, we moved on to music issues, but then, Amy mentioned once, at a holiday party, no one was able to play music because no one had any songs that were not explicit.
Then, I had a light bulb go off! I had literally just finished working on a forced aligner that works in high noise audio files (Github repo available @ Canetis). We could easily use this aligner to find all occurrences of expletives and remove them. Immediately, we got to work: I connect my teammates with a nice Flask tutorial and a good reference website to check for their HTML needs and was overall available for any big issues they had. Then Tejas and I got to work on integrating Canetis into our backend, and then worked on the actual dubbing process. Development went unbelievable smoothly and by 2 AM that night, we had our explicit dubber working perfectly! At this point, I made a github repo when divine inspiration hit me for the name: CleanBeats.ai, cause anything sounds cooler with ai at the end of it.
But then, we had about 24 hours more to kill. So we decided, instead of just dubbing the word, what if we made it so you could replace the word with any other word of your choosing. However, we were primarily using songs as our test files: imagine jamming Siri’s voice into the middle of an Eminem Song. It wouldn’t work.
So our challenge for the rest of the weekend was essentially to build a model that could automatically run style transfer on audio files seeded with a text to speech generated audio and the context surrounding the word: so essentially a GAN
Since we were at Santa Barbara, Tejas and I decided, what better place is there to figure out our GAN model architecture than right by the beach 2 minutes away from us. ML+Beach=Dreams_Are_Real :). So the model we came up with for our generator, was a network that takes a 2 second audio clip as input. This audio clip would have the desired word removed and replaced with a synthetic text-to-speech library called gTTS. We would train that model using the classic Generator/Discriminator architecture, which you can read more about here, or you can just look up GAN online.
So having figured that out, we got to work building up our dataset. Since we had a forced aligner at our disposal, it was reasonable for us to build up a the neccessary dataset by using the times of each word to clip the audio file into a series of 3 second clips. We saved one numpy array that stored only the unedited audiofile and another with the synthetic speech spliced in. 3 songs in, however, and realized that we actually would be able to integrate our dataset creation into the process of dubbing out the explitives in our audio file. After some reworking and debugging, we eventually were able to create a true data pipeline each time that our CleanBeats explitive remover was used.
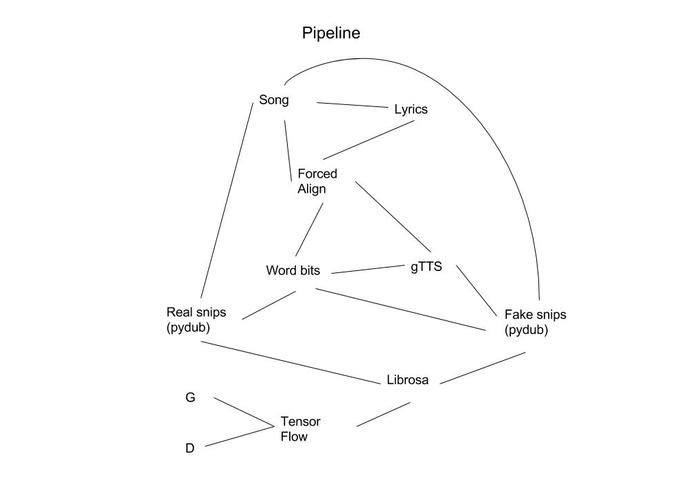
By the time we finally finished this pipeline, it was about 1 AM. There’s a saying that it’s impossible to make good decisions after midnight: this wisdom especially applies to training Machine Learning Models. We had a rough go at it. I was looking around the Hackathon, looking at all these crazy VR or Google Cloud projects just taking off and being tested all around me, my generator simply not producing the results I wanted, and me just making stupid mistakes, and I was starting to just feel kind of discouraged. I wasn’t expecting to make a top hackathon project or anything, but I just really wanted to make something that worked, and at this point, it was looking like we weren’t even going to finish training our model, much less integrate it and deploy it.
After a few hours, we were able to build and train a model that at least demonstrated our proof of concept that our generator improve the flow of the dubbed audio, even if it didn’t work nearly as well as expected. I was 50/50 on even demoing because I didn’t feel we had even finished, but the other three members of our team has put good effort into the front end and web-interface of our site, so I sucked it up, drank a little milk, and patched together our explicit dubber and our pipeline functions together with their website, and finished about 2 minutes before the submission deadline.

Afterwards, I was very glad I demoed! It was a super fun experience, having people and judges just walking around, asking about your project, and not in a polite way or anything: people seemed genuinely curious how everything worked and I had some great conversations about potential ways to improve our models/pipeline and even some really cool ideas of applications. People and even judges seemed really enthusiastic when talking with us about our project when talking with us at our booth, but I just kind of assumed that they were just being friendly/polite.
Then after the demo, we all sat down as a member of the staff thanked everyone for a great hackathon and went to announce the finalists. He then proceeded to name the finalist: I was pretty excited to see who would end up demoing because there were so many crazy awesome projects all around the demo area. He called out 2 team names, and then, for some reason, he said “CleanBeats.ai.”
I was just stunned! I was there at the demo! I saw so many other insane projects and ours was just a patching together of what I consider a series of reasonably simply python operations. It was software development at its most simple level. So I pretty sure it was just a fluke, that we just maybe pitched our code really well to the judges who stopped at our booth or something. I was just overall pumped and excited to have the chance to just talk about data pipelines and GANs to a group of people who were essentially a captive audience.
So I went up with my team, when it was our turn to demo. I didn’t think we were in actually contention so I was just super relaxed and had fun with it. I told some jokes as we were setting up our equipment, had some fun lip syncing to some Clean-Dubbed Eminem songs, and explaining data pipelines.
Then I just walked back, high-fived the team and said it was just awesome how far we got, given it was every single one of our first hackathons. All the other finalist projects that demoed were just amazing, and I just felt very honored to have finalled.
Then came all the sponsor prizes. We won honorable mention for the best use of ML in a project by LogMeIn, which was really cool. Then the judges came out, handed a slip of paper to the staff, and the announces came out and said “The winner of SBHacks 2018, $3000, and a 30 minute office hours at Y Combinator is …. Drumroll
…
Fly.ai”
Which entirely deserved it. This team of two in a single weekend designed a way to track and analyze various metrics of an airplane simply through a phone. Absolutely crazy product. But SBHacks wasn’t over.
The announcer then took the podium, and announced ” The second place project of SBHacks 2018, and the winners of 4 free round trip SurfAir tickets and 30 minute office hours with Y combinator is … Drumroll
…
CleanBeats.ai”
What?
What?
The best way I can explain what’s going through my head is by recapping my Mom’s reaction when I told her: “Are you sure there wasn’t some mistake?” and “But you’re nobody. Real People are there to win!”
I was just blown away. I was floating on a high, just feeling so good. To me, this was the culmination of spending my summer spending hours a day learning programming from scratch, of spending my weekend nights at USC taking Machine Learning classes online, of the hours I put into my role at SAIL, and of the various project I developed on my own. I enjoyed the entire process, but it felt amazing to have that hard work pay off in such a big way. 🙂
Huge thank you to SBHacks for providing transportation, food, sleeping places that I unfortunately did not use, and overall just an amazing experience to a guy at his very first hackathon!
Definitely, if you’ve made it this far in the post, check out CleanBeats.ai:
DevPost Form Github Hackathon Demo
On a side note, I had a realization that was very eye opening to me that I want to share with anyone reading this. Even up to the demo, I did not think we had built anything particularly impressive. If I was asked to say what portion of project I thought were better than our, I would have said almost all of them, because people were doing and building such awesome things everywhere that I had no idea how to build. Because I, “Nobody,” as my Mom so kindly put it, was able to build CleanBeats.ai, I didn’t think it was particularly impressive. I think this just shows the trap CS people can fall into: it’s so easy to get lost in the muddle of libraries and API’s and projects that everyone around you is working with and using, that you feel you are always falling behind. The past few months, I had decided that I wanted to learn signal analysis, TensorFlow, Keras, and Data pipelining. I decided to ignore all the side-noise for the time being, to not worry about the latest library or API’s, and just focus on myself. It was a difficult challenge, even during the hackathon itself, but eventually, even though I still don’t think that CleanBeats was truly one of the top projects at the hackathon, that focus led me to be able to develop something that was genuinely original, technically advanced, and that I can say I’m genuinely proud of. Just a little thought for food.