
So for those of you who don’t know, I work as a student researcher at SAIL, a signal analysis lab at USC. To read more about my work with them, check out my earlier post in which I describe the various ongoing project at the lab.
My current main project, along with my friend Nihar Sheth whose github you can find here, has been the development of a forced alignment algorithm that works for long and/or noisy data. All the most prevalent open-sourced forced alignment libraries implement some variation of the Viterbi Algorithm, which you can read more about here. However, the issue with the Viterbi Algorithm is that errors add up over time: over time a large number of errors can cause the algorithm to search for words in the transcript at times far off from where they occur in the audio file. As a result, these libraries do not perform well on long and/or noisy audio files.
In order to solve this problem, our PI referred us to a paper proposing a method for limiting the effect of these misalignment errors called Moreno’s Algorithm. I covered the theoretical backing of this algorithm in my post Forced Alignment: Pregame. In this post, I’m going to go into the details of my actual implementation of this algorithm.
Now, to implement Moreno’s, we don’t need to start from scratch: there are a number of forced alignment libraries publicly available: we just need to develop a method to recursively run them on an audio file and transcript. We ended up choosing to work with the Gentle Forced Alignment Library because we felt it was the most clearly documented and organized library available to work with.
From there, we went to the whiteboard.

So in case our mental vomit that is this whiteboard is unclear, we essentially broke the proccess down into a few main components.
First in the abstract, we decided we would build a main function “align” that accepted an audio file path and a transcript file path and would hold all these moving components. From there, we also decided we would need a recursive function, which we innovatively named “recurse.” After debating a few recursive implementations, we decided that this function would take a list of Gentle word objects, which is the output of Gentle’s alignment function.
From there we essentially had to figure out how to take the gentle output we receive and restructure it so that we could recursively run Gentle on the non-anchor points. Any time we pass an audio and transcript to Gentle, Gentle will assume, naturally that it starts at 0, which is a problem if we are running Gentle recursively in order to more accurately align a single large audio file.
We broke the issue down three different measurements to keep track of: the number of aligned points, relative audio start times, and the transcript positions. In order to easily track these constantly changing values, we decided we would create a “Segment” class. This class would be used to store stretches of anchored and anchored Gentle word objects. This class would also hold the audio start and end time relative, the gentle output of word objects, a bool that tells whether the Segment is an anchor point or not, and an integer tracking its parent segment’s length, which we later use as one of our recursive base cases.
From there, we also implemented a “run_gentle()” function, which essentially accepts and audio file path and a string, runs the gentle aligner, and then updates the gentle alignment data to set the times relative to the main audio file, rather than that specific segment.
Finally, we got to our primary function: “segmentizer().” This function accepted a list of gentle word objects as input, and a integer anchor length. From there, it iterated through the list of word object and as soon as it reached the end of the anchor, it stored the previous unanchored stretch of words as an unanchored Segment object and the current anchor segment as an anchored Segment object.
While we naturally had a series of bugs and unforeseen issues arise throughout the development process, we have now officially tested and released our forced aligner Canetis. We are almost finished with an install script, but for now, you can check out the code and download Canetis here.
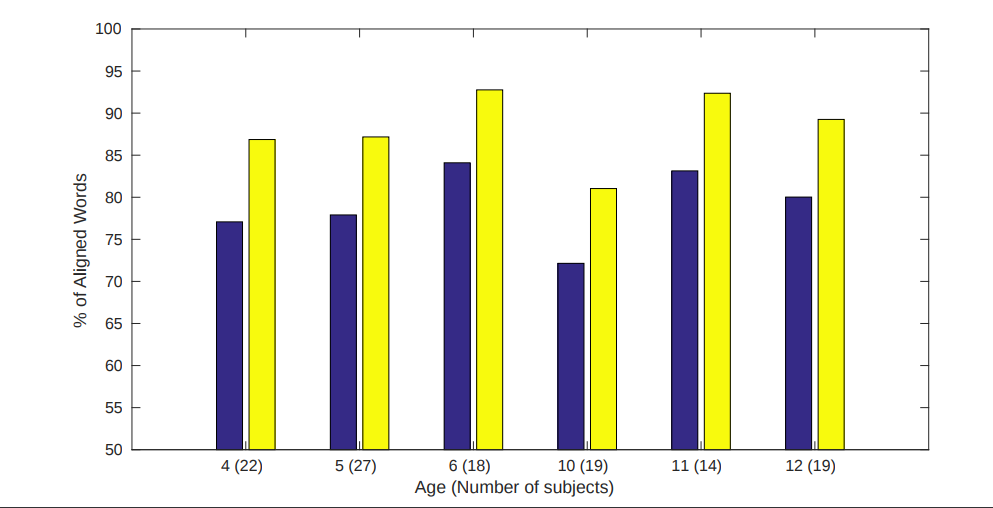
Over the weekend, we ran Canetis on around 80 hours of noisy/long audio files that our lab needed aligned, and during this process, we saved statistics on both Gentle’s and Canetis’s Alignment Performance. There are still a few hyper-parameters, such as the rate of our anchor length decay, that we are still tuning but it clearly makes a non-trivial improvement over Gentle’s original output.
Also, a great application for forced alignment, which you will be able to read about soon in my next post, that I think people have really been sleeping on, is using it to build up domain specific Audio-based data pipelines.
A little teaser for my next post ;). Happy digging!