
While the forced aligner for the forensic interview project is being developed, we are looking ahead at what other model we will need to build in order to extract useful features from our interview files. One feature that jumped out very quickly would be the simple question of who is speaking: a child or an adult?
Because any models used to analyze adult/child interviews will be entirely dependent on the data generated by this classifier, a high level of accuracy is absolutely critical. This ought to be an easy classifier to build, but the data constraints surrounding this model make it a little more challenging that building a basic audio analysis.
The first constraint is simply that of data acquisition. There are obviously no re-labelled data sets of child/adult audio classification. We will simply be using our adult-only or child-only segments of our own interview transcripts.
However, a more pressing constraint, because we want this model to generalize as a universal child/adult classifier beyond our data set for future projects, we have to make sure that our model does not fit features that are specific to only our particular training data. In order to solve this problem, we are going to train our model not only to accurately classify a speaker as a child or adult, but also to inaccurately classify the domain of a particular audio clip.
To build such a model, we are referring to a paper published at Cornell which introduces the idea of the gradient reversal layer. Essentially, this paper demonstrates that, given a shared convolution foundation, the sum of back-propagation of 2 different fully connected models stacked on this convolution layer is equivalent to training the convolution foundation separately with each fully connected model.
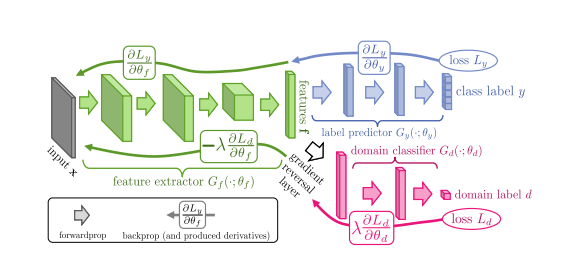
(a visual representation of a flipped gradient)
Our lab has access to one large data set of about 60,000 child/adult speech examples, which we will be using as our primary training data for our model, as well as 2 other sets of about 10,000 examples, which we will be including in our training data as well, but especially leveraging for its potential benefits within the gradient reversal layer.
So these are my two main projects I’m working on at SAIL. The scaled forced aligner is almost finished, which I will post about as soon as I have completed and tested it. If you want to read more about gradient reversal layers, you can find the paper at this link: https://arxiv.org/pdf/1505.07818.pdf.
I’m excited to start digging 🙂