
Hope ya’ll’s day is going well! In my last post, I talk about the lab, SAIL, that I’m working at and an overview of the ongoing projects at the lab. Today, I’m going to talk the specifics of my current role within the Forensic Interview Project.
For those of ya’ll who didn’t get the chance to read my last post, the problem that SAIL is currently trying to solve is the high level of
ambiguity that arises within potential cases of child trauma, specifically during the interviews of these children.
These situations are so emotionally charged that the most influential factor in determining a child’s responses during the interview isn’t the reality of their situation, but rather the way in which a lawyer approaches these children.
Working with the LA justice department, we have acquired the audio and transcripts of numerous interviews of such cases. From this data we are hoping to create a model that can recommend the optimal interview strategy for lawyers to find the truth in these situations.
As the freshman in the lab, I bet you can take a guess who is doing the data preprocessing ;). Fortunately, however, with this particular data set, even the preprocessing is a pretty exciting process.
My current task, working with my fellow freshman Nihar Sheth, is to develop a forced alignment model that scales efficiently to long audio files. The desired result would be an accurate return of the starting and ending point of each word within the audio file.

Fortunately, however, we are not building this model from scratch. We are using a forced alignment library called Gentle, which is built on top of Kaldi. In order to ensure an optimized level of accuracy within our large audio files, we are building an implementation of Moreno’s recursive algorithm on top of the Gentle Library.
In the paper “A Recursive Algorithm for the Forced Alignment of very Long Audio Segments, ” Moreno proposes a new recursive method of ensuring quality. Running a forced aligner down a long audio file creates a large possibility of misalignment due to small errors that accumulates over the course of the file.
In his paper, Moreno proposed the creation of these so-called “anchor points” in order to develop a isolate the segments of the audio that are correctly aligned. A stretch of audio is an anchor point if it contains N number of consecutive correctly aligned words.
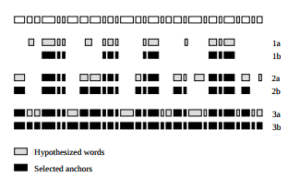
The larger the N, the more accurate the model will be. The smaller the N, the faster the model will be.
With these anchor points having been located, the model will then run recursively on each individual non-anchored section of audio. This isolation of dis-aligned clips can eventually prevent errors in the transcript or audio from causing misalignment in other areas by constricting their effect small portions of audio.
I’ve spent the past week reading related research papers on this topic of optimizing forced alignment, as well as playing around and growing familiar with the gentle library. The next few days, Nihar and I will be developing the pseudo-code and the implementation of Moreno’s algorithm built on top of gentle. The Pre-Game was fun, but it’s over now. It’s time to move away from these somewhat abstract concepts to the functional implementation. I’ll let ya’ll know how the game goes!
Post Scriptum,
If ya’ll want to get a fantastic, in-depth of Moreno’s algorithm, you can find the actual paper right here. It’s a barely 5 pages, and absolutely worth it: https://pdfs.semanticscholar.org/5aab/9a55e3ced09929d3644b971085620cae22e4.pdf
Also, definitely check out the Gentle library! We had some trouble with the download, but it is a fantastic tool that is extremely easy to use to transcribe and align audio. Find it here:
https://github.com/lowerquality/gentle